Fine-grained FP8
Fine-grained FP8 quantization quantizes the weights and activations to fp8.
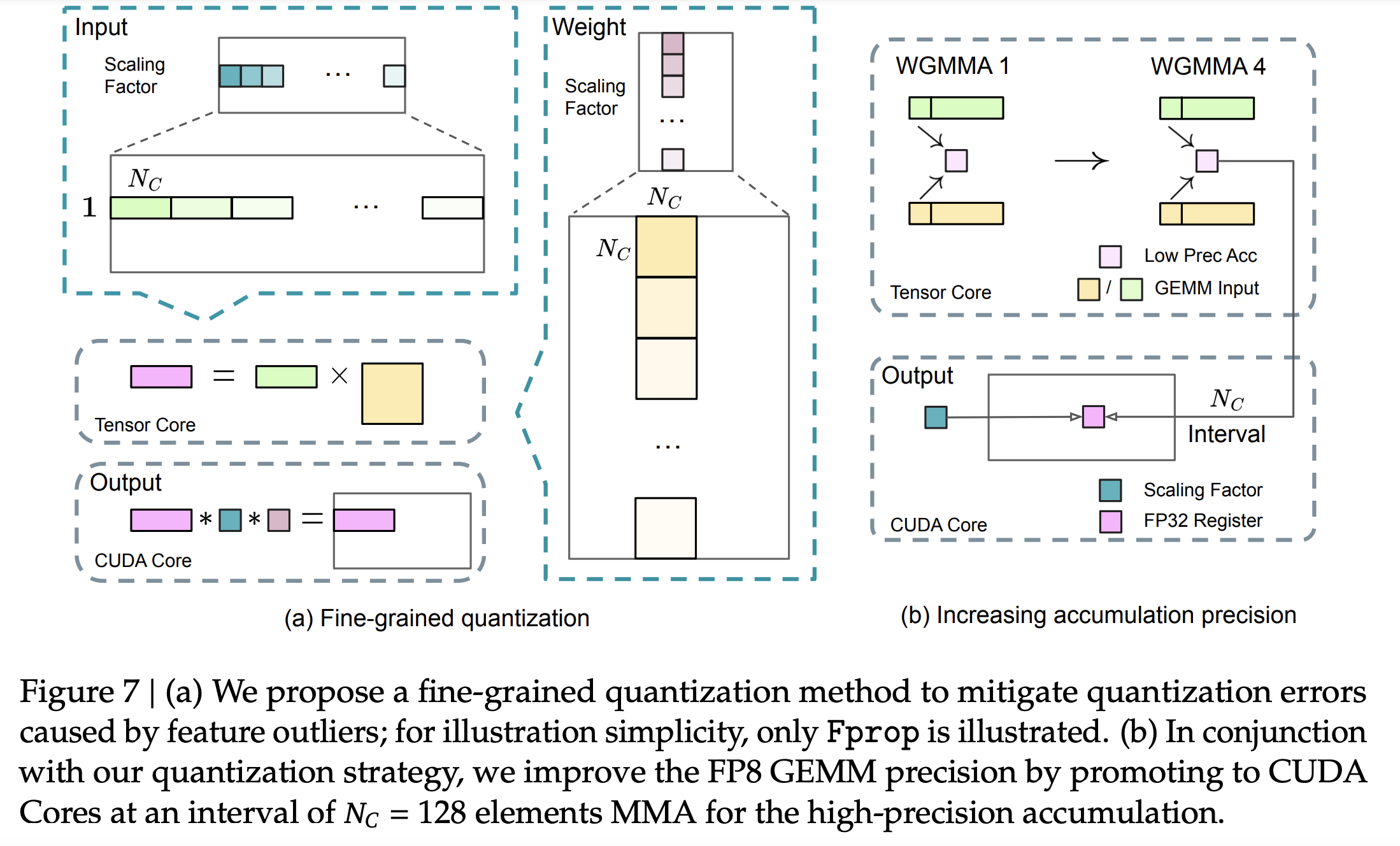
- The weights are quantized to 8-bits for each 2D block (
weight_block_size=(128, 128)). - The activations are quantized to 8-bits for each group per token. The group value matches the weights in the input channel (128 by default).
FP8 quantization enables support for DeepSeek-V3 and DeepSeek-R1.
Install Accelerate and upgrade to the latest version of PyTorch.
pip install --upgrade accelerate torchCreate a FineGrainedFP8Config class and pass it to from_pretrained to quantize it. The weights are loaded in full precision (torch.float32) by default regardless of the actual data type the weights are stored in. Set dtype="auto" to load the weights in the data type defined in a models config.json file to automatically load the most memory-optiomal data type.
from transformers import FineGrainedFP8Config, AutoModelForCausalLM, AutoTokenizer
model_name = "meta-llama/Meta-Llama-3-8B"quantization_config = FineGrainedFP8Config()quantized_model = AutoModelForCausalLM.from_pretrained(model_name, dtype="auto", device_map="auto", quantization_config=quantization_config)
tokenizer = AutoTokenizer.from_pretrained(model_name)input_text = "What are we having for dinner?"input_ids = tokenizer(input_text, return_tensors="pt").to(quantized_model.device.type)
output = quantized_model.generate(**input_ids, max_new_tokens=10)print(tokenizer.decode(output[0], skip_special_tokens=True))Use save_pretrained to save the quantized model and reload it with from_pretrained.
quant_path = "/path/to/save/quantized/model"model.save_pretrained(quant_path)model = AutoModelForCausalLM.from_pretrained(quant_path, device_map="auto")