ZoeDepth
This model was released on 2023-02-23 and added to Hugging Face Transformers on 2024-07-08.

ZoeDepth
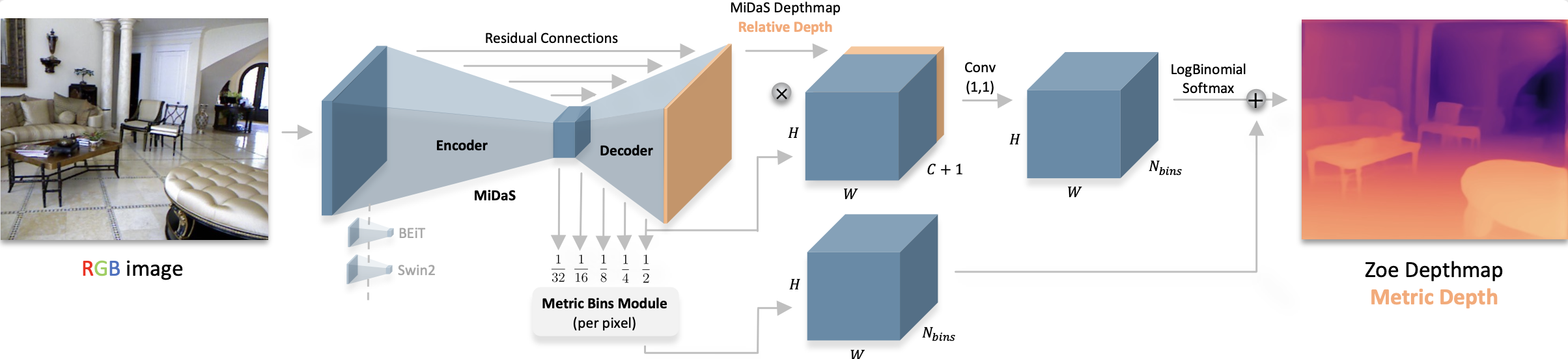
Section titled “ZoeDepth”ZoeDepth is a depth estimation model that combines the generalization performance of relative depth estimation (how far objects are from each other) and metric depth estimation (precise depth measurement on metric scale) from a single image. It is pre-trained on 12 datasets using relative depth and 2 datasets (NYU Depth v2 and KITTI) for metric accuracy. A lightweight head with a metric bin module for each domain is used, and during inference, it automatically selects the appropriate head for each input image with a latent classifier.
You can find all the original ZoeDepth checkpoints under the Intel organization.
The example below demonstrates how to estimate depth with Pipeline or the AutoModel class.
import requestsimport torchfrom transformers import pipelinefrom PIL import Image
url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"image = Image.open(requests.get(url, stream=True).raw)pipeline = pipeline( task="depth-estimation", model="Intel/zoedepth-nyu-kitti", dtype=torch.float16, device=0)results = pipeline(image)results["depth"]import torchimport requestsfrom PIL import Imagefrom transformers import AutoModelForDepthEstimation, AutoImageProcessor
image_processor = AutoImageProcessor.from_pretrained( "Intel/zoedepth-nyu-kitti")model = AutoModelForDepthEstimation.from_pretrained( "Intel/zoedepth-nyu-kitti", device_map="auto")url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"image = Image.open(requests.get(url, stream=True).raw)inputs = image_processor(image, return_tensors="pt").to(model.device)
with torch.no_grad(): outputs = model(inputs)
# interpolate to original size and visualize the prediction## ZoeDepth dynamically pads the input image, so pass the original image size as argument## to `post_process_depth_estimation` to remove the padding and resize to original dimensions.post_processed_output = image_processor.post_process_depth_estimation( outputs, source_sizes=[(image.height, image.width)],)
predicted_depth = post_processed_output[0]["predicted_depth"]depth = (predicted_depth - predicted_depth.min()) / (predicted_depth.max() - predicted_depth.min())depth = depth.detach().cpu().numpy() * 255Image.fromarray(depth.astype("uint8"))-
In the original implementation ZoeDepth performs inference on both the original and flipped images and averages the results. The
post_process_depth_estimationfunction handles this by passing the flipped outputs to the optionaloutputs_flippedargument as shown below.with torch.no_grad():outputs = model(pixel_values)outputs_flipped = model(pixel_values=torch.flip(inputs.pixel_values, dims=[3]))post_processed_output = image_processor.post_process_depth_estimation(outputs,source_sizes=[(image.height, image.width)],outputs_flipped=outputs_flipped,)
Resources
Section titled “Resources”- Refer to this notebook for an inference example.
ZoeDepthConfig
Section titled “ZoeDepthConfig”[[autodoc]] ZoeDepthConfig
ZoeDepthImageProcessor
Section titled “ZoeDepthImageProcessor”[[autodoc]] ZoeDepthImageProcessor - preprocess
ZoeDepthImageProcessorFast
Section titled “ZoeDepthImageProcessorFast”[[autodoc]] ZoeDepthImageProcessorFast - preprocess
ZoeDepthForDepthEstimation
Section titled “ZoeDepthForDepthEstimation”[[autodoc]] ZoeDepthForDepthEstimation - forward