Mistral
This model was released on 2023-10-10 and added to Hugging Face Transformers on 2023-09-27.




Mistral
Section titled “Mistral”Mistral is a 7B parameter language model, available as a pretrained and instruction-tuned variant, focused on balancing the scaling costs of large models with performance and efficient inference. This model uses sliding window attention (SWA) trained with a 8K context length and a fixed cache size to handle longer sequences more effectively. Grouped-query attention (GQA) speeds up inference and reduces memory requirements. Mistral also features a byte-fallback BPE tokenizer to improve token handling and efficiency by ensuring characters are never mapped to out-of-vocabulary tokens.
You can find all the original Mistral checkpoints under the Mistral AI_ organization.
The example below demonstrates how to chat with Pipeline or the AutoModel, and from the command line.
>>> import torch>>> from transformers import pipeline
>>> messages = [... {"role": "user", "content": "What is your favourite condiment?"},... {"role": "assistant", "content": "Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!"},... {"role": "user", "content": "Do you have mayonnaise recipes?"}... ]
>>> chatbot = pipeline("text-generation", model="mistralai/Mistral-7B-Instruct-v0.3", dtype=torch.bfloat16, device=0)>>> chatbot(messages)>>> import torch>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-Instruct-v0.3", dtype=torch.bfloat16, attn_implementation="sdpa", device_map="auto")>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-Instruct-v0.3")
>>> messages = [... {"role": "user", "content": "What is your favourite condiment?"},... {"role": "assistant", "content": "Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!"},... {"role": "user", "content": "Do you have mayonnaise recipes?"}... ]
>>> model_inputs = tokenizer.apply_chat_template(messages, return_tensors="pt").to(model.device)
>>> generated_ids = model.generate(model_inputs, max_new_tokens=100, do_sample=True)>>> tokenizer.batch_decode(generated_ids)[0]"Mayonnaise can be made as follows: (...)"echo -e "My favorite condiment is" | transformers chat mistralai/Mistral-7B-v0.3 --dtype auto --device 0 --attn_implementation flash_attention_2Quantization reduces the memory burden of large models by representing the weights in a lower precision. Refer to the Quantization overview for more available quantization backends.
The example below uses bitsandbytes to only quantize the weights to 4-bits.
>>> import torch>>> from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
>>> # specify how to quantize the model>>> quantization_config = BitsAndBytesConfig(... load_in_4bit=True,... bnb_4bit_quant_type="nf4",... bnb_4bit_compute_dtype="torch.float16",... )
>>> model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-Instruct-v0.3", quantization_config=True, dtype=torch.bfloat16, device_map="auto")>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-Instruct-v0.3")
>>> prompt = "My favourite condiment is"
>>> messages = [... {"role": "user", "content": "What is your favourite condiment?"},... {"role": "assistant", "content": "Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!"},... {"role": "user", "content": "Do you have mayonnaise recipes?"}... ]
>>> model_inputs = tokenizer.apply_chat_template(messages, return_tensors="pt").to(model.device)
>>> generated_ids = model.generate(model_inputs, max_new_tokens=100, do_sample=True)>>> tokenizer.batch_decode(generated_ids)[0]"The expected output"Use the AttentionMaskVisualizer to better understand what tokens the model can and cannot attend to.
>>> from transformers.utils.attention_visualizer import AttentionMaskVisualizer
>>> visualizer = AttentionMaskVisualizer("mistralai/Mistral-7B-Instruct-v0.3")>>> visualizer("Do you have mayonnaise recipes?")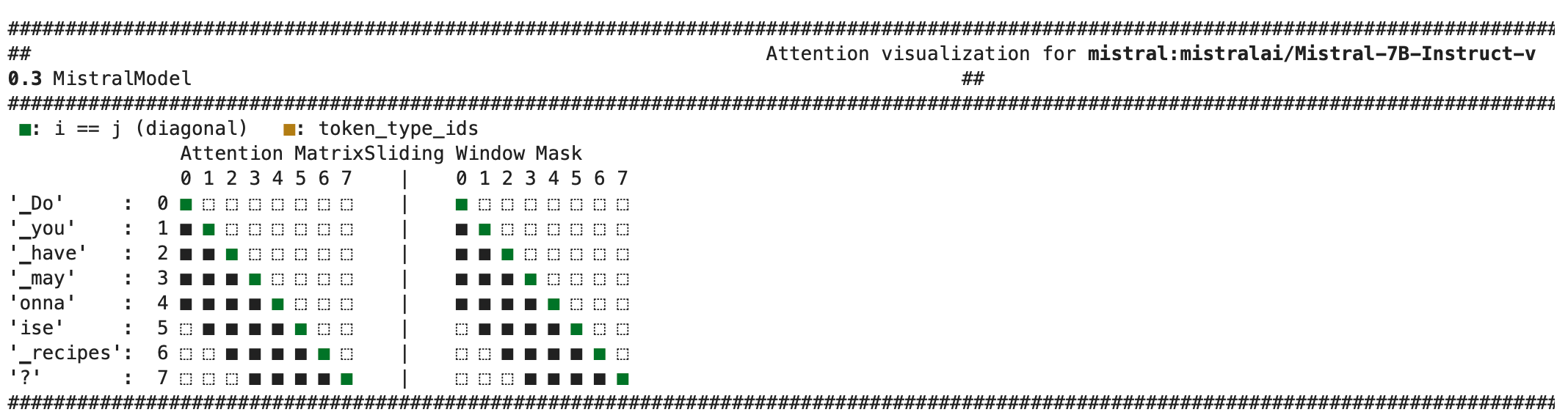
MistralConfig
Section titled “MistralConfig”[[autodoc]] MistralConfig
MistralCommonBackend
Section titled “MistralCommonBackend”[[autodoc]] MistralCommonBackend
MistralModel
Section titled “MistralModel”[[autodoc]] MistralModel - forward
MistralForCausalLM
Section titled “MistralForCausalLM”[[autodoc]] MistralForCausalLM - forward
MistralForSequenceClassification
Section titled “MistralForSequenceClassification”[[autodoc]] MistralForSequenceClassification - forward
MistralForTokenClassification
Section titled “MistralForTokenClassification”[[autodoc]] MistralForTokenClassification - forward
MistralForQuestionAnswering
Section titled “MistralForQuestionAnswering”[[autodoc]] MistralForQuestionAnswering - forward