KOSMOS-2.5
This model was released on 2023-09-20 and added to Hugging Face Transformers on 2025-08-19.



KOSMOS-2.5
Section titled “KOSMOS-2.5”The Kosmos-2.5 model was proposed in KOSMOS-2.5: A Multimodal Literate Model by Microsoft.
The abstract from the paper is the following:
We present Kosmos-2.5, a multimodal literate model for machine reading of text-intensive images. Pre-trained on large-scale text-intensive images, Kosmos-2.5 excels in two distinct yet cooperative transcription tasks: (1) generating spatially-aware text blocks, where each block of text is assigned its spatial coordinates within the image, and (2) producing structured text output that captures styles and structures into the markdown format. This unified multimodal literate capability is achieved through a shared Transformer architecture, task-specific prompts, and flexible text representations. We evaluate Kosmos-2.5 on end-to-end document-level text recognition and image-to-markdown text generation. Furthermore, the model can be readily adapted for any text-intensive image understanding task with different prompts through supervised fine-tuning, making it a general-purpose tool for real-world applications involving text-rich images. This work also paves the way for the future scaling of multimodal large language models.
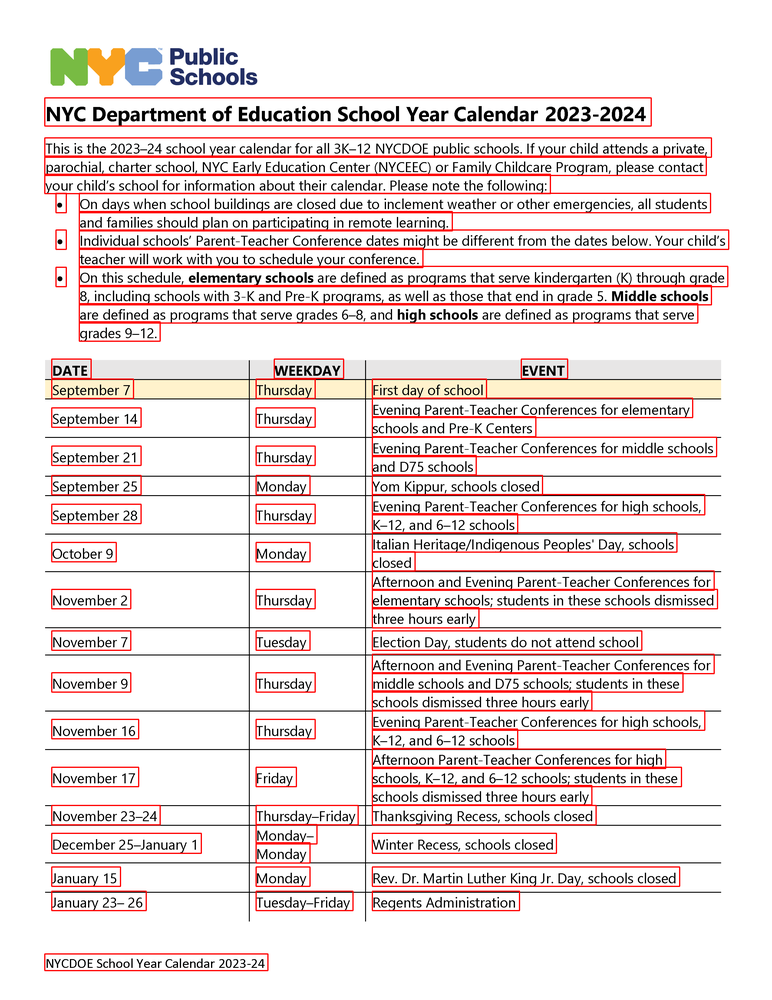
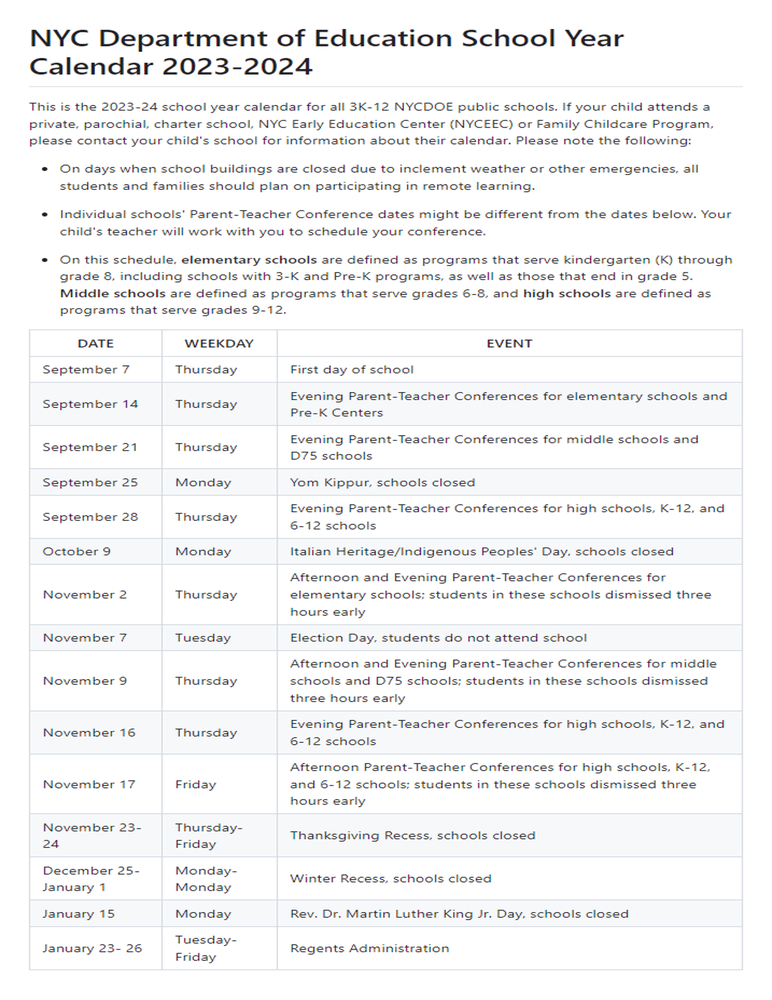
Overview of tasks that KOSMOS-2.5 can handle. Taken from the original paper.
The examples below demonstrates how to generate with AutoModel, for both Markdown and OCR tasks.
import reimport torchimport requestsfrom PIL import Image, ImageDrawfrom transformers import AutoProcessor, Kosmos2_5ForConditionalGenerationfrom accelerate import Accelerator
repo = "microsoft/kosmos-2.5"device = "cuda:0"dtype = torch.bfloat16model = Kosmos2_5ForConditionalGeneration.from_pretrained(repo, device_map=device, dtype=dtype)processor = AutoProcessor.from_pretrained(repo)
# sample imageurl = "https://huggingface.co/microsoft/kosmos-2.5/resolve/main/receipt_00008.png"image = Image.open(requests.get(url, stream=True).raw)
prompt = "<md>"inputs = processor(text=prompt, images=image, return_tensors="pt")
height, width = inputs.pop("height"), inputs.pop("width")raw_width, raw_height = image.sizescale_height = raw_height / heightscale_width = raw_width / width
inputs = {k: v.to(device) if v is not None else None for k, v in inputs.items()}inputs["flattened_patches"] = inputs["flattened_patches"].to(dtype)generated_ids = model.generate( **inputs, max_new_tokens=1024,)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)print(generated_text[0])import reimport torchimport requestsfrom PIL import Image, ImageDrawfrom transformers import AutoProcessor, Kosmos2_5ForConditionalGenerationfrom accelerate import Accelerator
repo = "microsoft/kosmos-2.5"device = "cuda:0"dtype = torch.bfloat16model = Kosmos2_5ForConditionalGeneration.from_pretrained(repo, device_map=device, dtype=dtype)processor = AutoProcessor.from_pretrained(repo)
# sample imageurl = "https://huggingface.co/microsoft/kosmos-2.5/resolve/main/receipt_00008.png"image = Image.open(requests.get(url, stream=True).raw)
# bs = 1prompt = "<ocr>"inputs = processor(text=prompt, images=image, return_tensors="pt")height, width = inputs.pop("height"), inputs.pop("width")raw_width, raw_height = image.sizescale_height = raw_height / heightscale_width = raw_width / width
# bs > 1, batch generation# inputs = processor(text=[prompt, prompt], images=[image,image], return_tensors="pt")# height, width = inputs.pop("height"), inputs.pop("width")# raw_width, raw_height = image.size# scale_height = raw_height / height[0]# scale_width = raw_width / width[0]
inputs = {k: v.to(device) if v is not None else None for k, v in inputs.items()}inputs["flattened_patches"] = inputs["flattened_patches"].to(dtype)generated_ids = model.generate( **inputs, max_new_tokens=1024,)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)def post_process(y, scale_height, scale_width): y = y.replace(prompt, "") if "<md>" in prompt: return y pattern = r"<bbox><x_\d+><y_\d+><x_\d+><y_\d+></bbox>" bboxs_raw = re.findall(pattern, y) lines = re.split(pattern, y)[1:] bboxs = [re.findall(r"\d+", i) for i in bboxs_raw] bboxs = [[int(j) for j in i] for i in bboxs] info = "" for i in range(len(lines)): box = bboxs[i] x0, y0, x1, y1 = box if not (x0 >= x1 or y0 >= y1): x0 = int(x0 * scale_width) y0 = int(y0 * scale_height) x1 = int(x1 * scale_width) y1 = int(y1 * scale_height) info += f"{x0},{y0},{x1},{y0},{x1},{y1},{x0},{y1},{lines[i]}" return info
output_text = post_process(generated_text[0], scale_height, scale_width)print(output_text)
draw = ImageDraw.Draw(image)lines = output_text.split("\n")for line in lines: # draw the bounding box line = list(line.split(",")) if len(line) < 8: continue line = list(map(int, line[:8])) draw.polygon(line, outline="red")image.save("output.png")Chat version
Section titled “Chat version”The authors also released Kosmos-2.5 Chat, which is a chat version optimized for document understanding. You can use it like so:
import reimport torchimport requestsfrom PIL import Image, ImageDrawfrom transformers import AutoProcessor, Kosmos2_5ForConditionalGeneration
repo = "microsoft/kosmos-2.5-chat"device = "cuda:0"dtype = torch.bfloat16
model = Kosmos2_5ForConditionalGeneration.from_pretrained(repo, device_map=device, torch_dtype=dtype, attn_implementation="flash_attention_2")processor = AutoProcessor.from_pretrained(repo)
# sample imageurl = "https://huggingface.co/microsoft/kosmos-2.5/resolve/main/receipt_00008.png"
image = Image.open(requests.get(url, stream=True).raw)
question = "What is the sub total of the receipt?"template = "<md>A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions. USER: {} ASSISTANT:"prompt = template.format(question)inputs = processor(text=prompt, images=image, return_tensors="pt")
height, width = inputs.pop("height"), inputs.pop("width")raw_width, raw_height = image.sizescale_height = raw_height / heightscale_width = raw_width / width
inputs = {k: v.to(device) if v is not None else None for k, v in inputs.items()}inputs["flattened_patches"] = inputs["flattened_patches"].to(dtype)generated_ids = model.generate( **inputs, max_new_tokens=1024,)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)print(generated_text[0])Kosmos2_5Config
Section titled “Kosmos2_5Config”[[autodoc]] Kosmos2_5Config
Kosmos2_5ImageProcessor
Section titled “Kosmos2_5ImageProcessor”[[autodoc]] Kosmos2_5ImageProcessor - preprocess
Kosmos2_5ImageProcessorFast
Section titled “Kosmos2_5ImageProcessorFast”[[autodoc]] Kosmos2_5ImageProcessorFast - preprocess
Kosmos2_5Processor
Section titled “Kosmos2_5Processor”[[autodoc]] Kosmos2_5Processor
Kosmos2_5Model
Section titled “Kosmos2_5Model”[[autodoc]] Kosmos2_5Model - forward
Kosmos2_5ForConditionalGeneration
Section titled “Kosmos2_5ForConditionalGeneration”[[autodoc]] Kosmos2_5ForConditionalGeneration - forward