Doge
This model was released on 2024-12-27 and added to Hugging Face Transformers on 2025-07-08.
Overview
Section titled “Overview”Doge is a series of small language models based on the Doge architecture, aiming to combine the advantages of state-space and self-attention algorithms, calculate dynamic masks from cached value states using the zero-order hold method, and solve the problem of existing mainstream language models getting lost in context. It uses the wsd_scheduler scheduler to pre-train on the smollm-corpus, and can continue training on new datasets or add sparse activation feedforward networks from stable stage checkpoints.
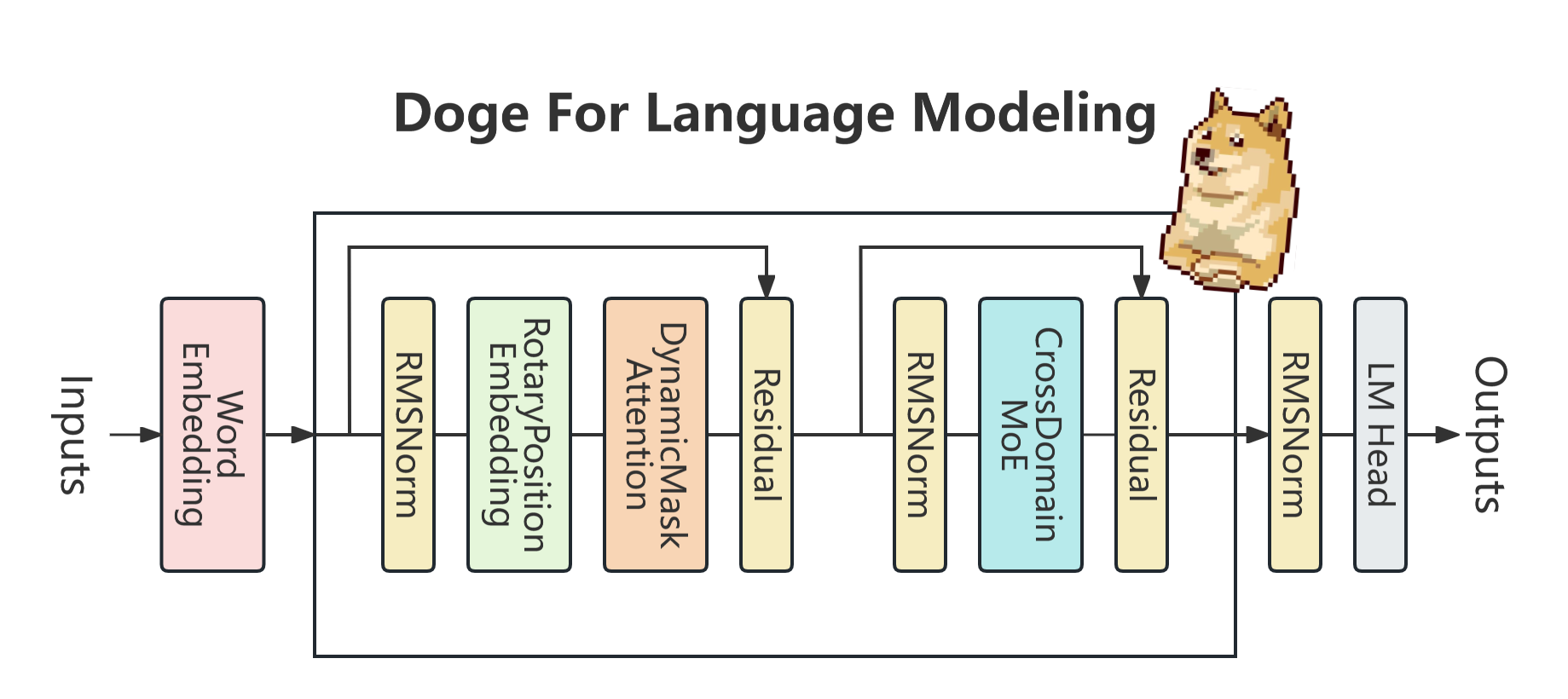
As shown in the figure below, the sequence transformation part of the Doge architecture uses Dynamic Mask Attention, which can be understood as using self-attention related to value states during training, and using state-space without past state decay during inference, to solve the problem of existing Transformers or SSMs getting lost in long text. The state transformation part of Doge uses Cross Domain Mixture of Experts, which consists of dense linear layers and sparse embedding layers, and can additionally increase sparse parameters to continue training from dense weight checkpoints without retraining the entire model, thereby reducing the cost of continuous iteration of the model. In addition, Doge also uses RMSNorm and Residual with learnable parameters to adapt the gradient range of deep models.
Checkout all Doge model checkpoints here.
Using Doge-Base for text generation
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("SmallDoge/Doge-20M")model = AutoModelForCausalLM.from_pretrained("SmallDoge/Doge-20M")inputs = tokenizer("Hey how are you doing?", return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=100)print(tokenizer.batch_decode(outputs))Using Doge-Instruct for question answering
from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig, TextStreamer
tokenizer = AutoTokenizer.from_pretrained("SmallDoge/Doge-20M-Instruct")model = AutoModelForCausalLM.from_pretrained("SmallDoge/Doge-20M-Instruct")
generation_config = GenerationConfig( max_new_tokens=100, use_cache=True, do_sample=True, temperature=0.8, top_p=0.9, repetition_penalty=1.0)steamer = TextStreamer(tokenizer=tokenizer, skip_prompt=True)
prompt = "Hi, how are you doing today?"conversation = [ {"role": "user", "content": prompt}]inputs = tokenizer.apply_chat_template( conversation=conversation, tokenize=True, return_tensors="pt",)
outputs = model.generate( inputs, tokenizer=tokenizer, generation_config=generation_config, streamer=steamer)DogeConfig
Section titled “DogeConfig”[[autodoc]] DogeConfig
DogeModel
Section titled “DogeModel”[[autodoc]] DogeModel - forward
DogeForCausalLM
Section titled “DogeForCausalLM”[[autodoc]] DogeForCausalLM - forward
DogeForSequenceClassification
Section titled “DogeForSequenceClassification”[[autodoc]] DogeForSequenceClassification - forward